FOMO to Flow: Building Gen AI Solutions
- 13 minutes read - 2716 wordsUnlock the power of Generative AI by learning to interact with large language models programmatically—and take it further with fine-tuning for customized responses.
If you’re a software maker feeling the fear of missing out (FOMO) on the Gen AI revolution, you’re not alone. The way we build and interact with software is evolving rapidly. “Google it” or “check Stack Overflow” is no longer the go-to approach — AI-first, conversational tools are becoming the new standard across development, design, and decision-making. Simply using tools like ChatGPT or Gemini as chatbots isn’t enough anymore. When even the biggest tech paradigms are being disrupted, what does that mean for traditional development roles?
Here’s the good news: it’s not too late to get started — and this guide will take you from FOMO to flow, introducing you to Gen AI concepts and showing you how to start building with confidence.
Let’s start by exploring the gen AI architecture that brings it all Gen AI concept together, and then we will get into developing Gen AI applications and practice these core concepts.
🏛️ Overview of Gen AI Architecture
More than a chatbot — building blocks of intelligent, context-aware applications
You’ve probably heard about LLMs — Large Language Models — floating around in conversations, headlines, or team meetings. They’re trained on gigantic amounts of text (imagine reading everything on Facebook, X, LinkedIn, and more), which helps them understand and generate human-like responses. Ask the right question (a.k.a. a prompt), and boom — you get a surprisingly good answer.
On their own, LLMs are a bit like goldfish. 🐟
They don’t remember what happened a moment ago, they don’t keep track of ongoing conversations or your specific context between interactions.
To build smart, conversational, and personalized Gen AI applications, you need more than just an LLM. You need a supporting architecture — a set of layers that provide memory, knowledge, and prompt optimization to help the AI feel more intelligent and useful. Here’s a quick look:
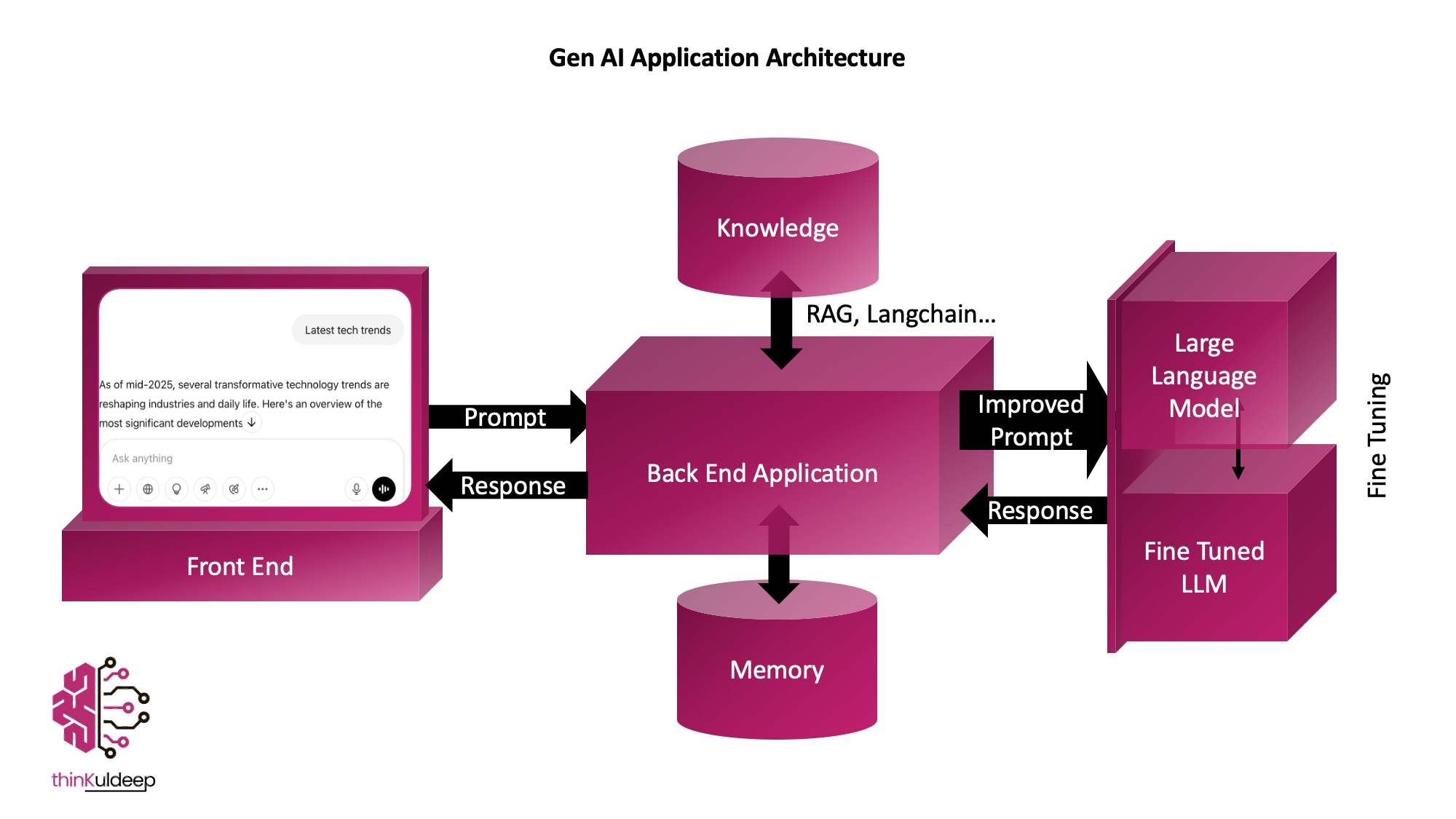
1. User Interface (Front End)
This is where the magic starts — from the user’s point of view. It might be a chat window, voice assistant, or a smart feature inside your app. The frontend captures input (text, images, voice) and displays responses in a way that suits your use case.
In tools like ChatGPT, users are expected to write clear prompts. That’s because LLMs — though incredibly knowledgeable — can’t read your mind. They respond best when you ask precisely. This is often called Prompt Engineering, but honestly, it’s more of a Prompting Art — knowing how to talk to the model so it truly understands what you want.
In business apps, the frontend may also help shape or enhance user input behind the scenes — so even vague questions become high-quality prompts before reaching the application layer.
2. Application Logic (Backend)
This is the brain behind the scenes. The backend handles user input, talks to the LLM, manages memory, adds relevant context, and delivers meaningful responses. Think of it as your app’s AI concierge, organizing everything to make the magic happen smoothly.
Here are the key component of application logic:
- 🧠 Memory System - LLMs don’t remember anything between interactions. To make conversations feel natural, your app needs to manage memory. A memory system stores previous interactions and sends important parts to the LLM as context with every prompt, so it can respond more intelligently — like remembering what the user asked earlier.
- 📚 Knowledge Base - LLMs are trained on general data — they might not know about you or or example about your company’s policies, product details, or niche topics. That’s where a Knowledge Base comes in.
This system retrieve relevant info from your own data (like FAQs, documents, or databases) and augment it to the user prompt before sending it to the LLM. This process is called Retrieval-Augmented Generation (RAG).
- The data is stored in a vector database, where each document/content is represented by a mathematical fingerprint (called an embedding).
- When a user asks something, we compare their query’s embedding to the stored embeddings (using similarity search) and fetch the most relevant content.
- This content is then injected into the prompt, giving the LLM exactly what it needs to give better, grounded answers.
Together, memory and knowledge retrieval make your Gen AI app feel smarter, more helpful, and deeply customized to your domain.
3. Large Language Models (LLMs)
At the heart of Gen AI applications are large language models like GPT, trained on massive datasets to understand and generate human-like language. These models are available through platforms such as Hugging Face, OpenAI, and others.
Fine-Tuning: A method to adapt a general-purpose, pre-trained LLM for specific business needs. Fine-tuning adjusts the model using domain-specific data, improving relevance and performance for targeted applications.
Some time we need to implement all of these concepts to achieve better result as per our business need. Next will develop all these concepts step by step.
👨🏽💻 Developing Gen AI Application
You might be surprised how easy it is to build your first Gen AI app. The best part? You don’t need to train your own LLM. Big players like OpenAI, Google, Anthropic, and Hugging Face already provide powerful models that you can use through simple APIs.
In this example, we’ll use Google’s Gemini API, which is still free within usage limits — perfect for trying things out.
Setup LLM APIs Access
- Sign up for Google Cloud (if you haven’t already). Enable the Gemini API
- Head over to Google AI Studio and create API key for your project.
Accessing Gen AI Model Programmatically
For simplicity, I’m using a Google Colab Notebook — no setup needed beyond your browser! But feel free to try this on your local machine too.
The fun part? 😀 You can even use Gen AI to help you write Gen AI code. Learning by doing the same in collab or in your favorite tool — what’s cooler than that?
👉 Developing First Gen AI Application — Colab Exercise
from google import genai
from google.colab import userdata
def query_gemini(prompt):
client = genai.Client(api_key=userdata.get('GOOGLE_API_KEY'))
response = client.models.generate_content(
model="gemini-2.0-flash",
contents=[prompt]
)
return response.text
prompt = "Tell me about Kuldeep"
print(query_gemini(prompt))
So, what happens here?
I ask the Gemini model: “Tell me about Kuldeep.” And it tries its best. But wait… the response might be generic. Something like:
“Kuldeep is a common name in India…” need more information…
That’s not what you were hoping for, right?
That’s because LLMs don’t know which Kuldeep you mean unless you give them more context.
This is where conversation and memory layers come into play. Let’s explore how to have a more meaningful interaction with the model in the next example by providing additional background during the conversation.
💬 Conversation for LLM
What you get from a Gen AI model heavily depends on how you ask. The better your prompt, the better the answer. This is where techniques like giving the model a persona, adding context, or showing examples come in — these are called one-shot or few-shot prompting.
Sometimes, a single prompt isn’t enough. Just like in real conversations, you might need to go back and forth, ask follow-ups, or break things down into steps. This is where ideas like chain of thought or tree of thought prompting help — guiding the AI step by step to a better outcome.
To have a proper conversation with an LLM we need implement memory component to store the conversations, and pass on with every conversation. And the good news? Gemini makes this easy with its built-in chat API that remembers what you’ve said.
👉 Check out the code notebook here:Developing a Chatbot with Gemini
Here’s a basic chatbot python program with memory:
from google import genai
from google.colab import userdata
client = genai.Client(api_key=userdata.get('GOOGLE_API_KEY'))
chat = client.chats.create(model="gemini-2.0-flash")
def run_chatbot():
print("Hello! I am thinkuldeep, how can I help you! Type 'quit' to exit.")
chat_history = []
while True:
user_input = input("You: ")
if user_input.lower() == 'quit':
print("thinkuldeep: Goodbye!")
break
response = chat.send_message(user_input)
print(f"thinkuldeep: {response.text}")
# Start the chatbot
run_chatbot()
Sample Conversation:
Hello! I am thinkuldeep, how can I help you! Type 'quit' to exit.
You: tell me about kuldeep
thinkuldeep: "Kuldeep" is a common name… can you give me more context?
You: he works at thoughtworks and wrote "Exploring the Metaverse"
thinkuldeep: Ah, you're likely referring to Kuldeep Singh… [gives useful details]
You: book title is "Exploring the Metaverse: Redefining the Reality in Digital Age"
thinkuldeep: Thanks! That helps narrow it down…
💡 As you can see, adding a bit more information helped the model give a more relevant answer. But it still can’t tell us, say, his contact info or specifics that aren’t popularly available in its training data.
In the next example, we’ll bring in custom knowledge and pass that knowledge to LLMs to get better response.
🧠 Implementing Basic RAG
Large Language Models (LLMs) like Gemini are powerful, but they aren’t all-knowing. They might not have the latest information about specific people, use cases, or private knowledge.
That’s where RAG comes in — Retrieval-Augmented Generation is a technique that fetches relevant information from an external source (like a website or document) and augments the prompt with this context before sending it to the LLM.
Let’s walk through a simple RAG implementation that pulls data from Kuldeep’s About page and uses it to generate accurate responses.
👉 Notebook: Implementing Basic RAG
🧩 1: Retrieve
Pull relevant information from the source page:
def retrive(url):
try:
response = requests.get(url)
soup = BeautifulSoup(response.content, "html.parser")
text_content = ""
for paragraph in soup.find_all("p"):
text_content += paragraph.get_text(strip=True) + "\n"
return text_content
except Exception as e:
return f"An error occurred: {e}"
✍️ 2: Augment
Inject the retrieved context into the prompt:
def augment(prompt, context):
return f"{prompt} where context is {context}"
💬 3: Generate
Send the augmented prompt to Gemini:
def generation(prompt):
client = genai.Client(api_key=userdata.get('GOOGLE_API_KEY'))
response = client.models.generate_content(
model="gemini-2.0-flash",
contents=[prompt]
)
return response.text
🚀 4: RAG in Action
prompt = "Tell me about Kuldeep"
context = retrive("https://thinkuldeep.com/about/")
improved_prompt = augment(prompt, context)
print(generation(improved_prompt))
That’s it! You’ll get a detailed response based on the real data from Kuldeep’s website. The second part of the same notebook integrates it in our chatbot example to initialize the context before chatting, and we get all accurate response in natural language.
Here’s a glimpse of how that interaction goes:
Hello! Ask me about Kuldeep Singh! Type 'quit' to exit.
You: how to contact him
thinkuldeep: Based on the provided info, you can reach Kuldeep via:
- 📧 thinkuldeep@gmail.com
- 💼 kuldeeps@thoughtworks.com
- 🔗 LinkedIn: kuldeep-reck
- 🐦 X (Twitter): thinkuldeep
- 📷 Instagram: thinkuldeep
- 📘 Facebook: kuldeep.reck
You: where does he work
thinkuldeep: He currently works at Thoughtworks as a Global Emerging Technology Leader and Principal Consultant.
You: does he write books
thinkuldeep: Yes! Kuldeep is the author of *"Exploring the Metaverse"* and *"MyThoughtworkings"*, and has contributed to others as well.
You: what is his next book
thinkuldeep: His upcoming book is titled *"Jagjivan – Living Larger than Life"*.
You: quit
thinkuldeep: Goodbye!
So we have seen RAG approach can give accurate, contextual answers by pulling in external information. This approach require all the contextual information to be passed along with the prompt, and that’s not practical and costly affair when using hosted LLMs. We need to augment the prompt with selected and most relevant context. Let’s understand it more in next section.
🧠 RAG using Embeddings and Similarity Search
As explained earlier, embeddings are numerical representations of text that capture semantic meaning. When we generate embeddings for all our contextual data and store them in a vector database, we create a searchable knowledge base.
These embeddings can then be compared to the user’s query using similarity metrics — like cosine similarity — to find the most relevant content. Once identified, that content can be appended to the user’s prompt to provide a more accurate and context-aware response from the LLM.
Let’s walk through how this works using Gemini APIs and a simple example. — 👉 RAG Using Embeddings and Similarity Search — GitHub
👷♀️ 1: Create Embeddings and Build the Knowledge Base
Let’s start by building a small dataset of page titles and URLs from thinkuldeep.com, and then generate embeddings using Gemini APIs.
genai.configure(api_key=userdata.get('GOOGLE_API_KEY'))
model = 'models/embedding-001'
def pageEmbeddings(title, text):
return genai.embed_content(model=model,
content=text,
task_type="retrieval_document",
title=title)["embedding"]
def knowledgeBase():
pages = [
{"title": "Open-sources and Community Applications", "content": "https://thinkuldeep.com/about/open-sources/"},
{"title": "Live Streaming, Webinars","content": "https://thinkuldeep.com/about/streaming/"},
{"title": "Patents Granted","content": "https://thinkuldeep.com/about/patents/"},
{"title": "Awards received and public coverage", "content": "https://thinkuldeep.com/about/recognitions/"},
{"title": "Me, my family and some moments, travel and trips", "content": "https://thinkuldeep.com/about/moments/"},
{ "title": "Book foreword, reviewed and authored", "content": "https://thinkuldeep.com/about/books/"}
]
df = pd.DataFrame(pages)
df.columns = ['Title', 'Url']
df['Embeddings'] = df.apply(lambda row: pageEmbeddings(row['Title'], row['Url']), axis=1)
return df
This creates a dataframe where each row contains a title, URL, and its corresponding embedding vector.
🔎 2: Find the Best Match with Similarity Search
Now, we search for the most relevant page based on the user’s input by comparing embedding similarity.
def findBestPage(query, dataframe):
query_embedding = genai.embed_content(model=model,
content=query,
task_type="retrieval_query")
dot_products = np.dot(np.stack(dataframe['Embeddings']), query_embedding["embedding"])
idx = np.argmax(dot_products)
return dataframe.iloc[idx]['Url']
prompt = "Tell me in brief Kuldeep's travels"
bestPage = findBestPage(prompt, knowledgeBase())
print(bestPage)
# Output: https://thinkuldeep.com/about/moments/
🤲 3: Implementing RAG with Context Augmentation
Now let’s use this best-matched page as additional context when generating a response.
def run_chatbot():
print("Hello! ask me about Kuldeep Singh! Type 'quit' to exit.")
generation(augment("", retrive("https://thinkuldeep.com/about/")))
df = knowledgeBase();
while True:
user_input = input("You: ")
if user_input.lower() == 'quit':
print("thinkuldeep: Goodbye!")
break
bestPageMatching = findBestPage(user_input, df)
response = generation(augment(user_input, retrive(bestPageMatching)))
print(f"thinkuldeep: {response.text} \n\n")
run_chatbot()
This chatbot dynamically retrieves and appends the most relevant context to the user’s query using similarity search and embeddings, resulting in richer, more accurate responses.
📻 Fine-Tuning
So far, we’ve worked with general-purpose LLMs using prompt engineering to steer their behavior. However, no matter how well we craft our prompts, public APIs and general models may still fall short of producing responses that align exactly with our desired tone, format, or accuracy.
That’s where fine-tuning comes into play.
Fine-tuning allows us to train a model on our own dataset, enabling it to respond in the specific way we want.
Below is a basic example of fine-tuning a Gemini model using Google’s Generative AI tools.
🔗 Link to the full notebook on GitHub
import google.generativeai as genai
from google.colab import userdata
import time
genai.configure(api_key=userdata.get('GOOGLE_API_KEY'))
basemodel = "models/gemini-1.5-flash-001-tuning"
trainingdata = [
{"text_input": "Who is Kuldeep", "output": "Hi, Thanks for Asking, Kuldeep Singh is a computer engineer with 20 years of IT experience. All the best - thinkuldeep.com"},
{"text_input": "Where does Kuldeep Work", "output": "Hi, Thanks for Asking, He works at Thoughtworks. All the best - thinkuldeep.com"},
# ... more training examples ...
]
operation = genai.create_tuned_model(
display_name="thinkuldeep",
source_model=basemodel,
epoch_count=5,
batch_size=4,
learning_rate=0.001,
training_data=trainingdata,
)
for status in operation.wait_bar():
time.sleep(10)
print(operation.result())
This would create a fine-tuned model something like this : tunedModels/thinkuldeep-1bja29uyplkib4xx1pcfer0yjhf5
Once created, we can use it like any other generative model:
genai.configure(api_key=userdata.get('GOOGLE_API_KEY'))
model = genai.GenerativeModel(model_name="tunedModels/thinkuldeep-1bja29uyplkib4xx1pcfer0yjhf5")
prompt = "Tell me about Kuldeep"
print(model.generate_content(prompt).text)
Hi, Thanks for Asking. He is a passionate AI engineer. All the best - thinkuldeep.com
Even with a very limited dataset, the model adapts to the style we trained it for — consistently using a polite opening and closing format. That’s the power of fine-tuning. Of course, real-world scenarios would require much larger and more diverse datasets, along with proper evaluation and validation processes.
🎯 Conclusion
We’ve now walked through several core concepts of Generative AI — from prompt engineering to embeddings, vector search, function calling, and finally, fine-tuning. These foundational techniques open up incredible opportunities for building intelligent, interactive, and personalized AI systems.
That said, this is just the beginning. The field of GenAI is vast and evolving rapidly. As we move forward, we must also recognize the ethical responsibilities that come with it. Building responsible, safe, and trustworthy AI requires:
- Transparent usage of data,
- Adherence to privacy standards,
- Thoughtful model alignment,
- And awareness of hallucination and misuse risks.
Always be cautious about the data you feed into prompts — it may inadvertently become part of training sets and surface in future responses. The industry still faces challenges in setting strong standards and guardrails for responsible use.
Let’s keep exploring, learning, and sharing as we shape the future of intelligent systems.
All the best — thinkuldeep.com 🙌
A variation of this article is originally published at AI Practices Publication
#evolution #ai #genai #technology #prompt #tutorial #learnings #fine-tuning #development #embeddings #similarity search #vector #database #tools